Whisper を Windows ローカルで使うための作業
概要
前置き
先月、Google Colab で Whisper を動かして音声をテキストに変換してブログを書いてみるという記事を投稿しました。
この方法は Google Colab で実行するので、高性能の GPU が使えて環境構築の手間がかからないというメリットがある一方で、毎回ライブラリをインストールする必要があって初期セットアップに時間がかかるというデメリットがありました。そこで、ローカル環境で Whisper を動かせば初期セットアップの時間を節約できると思い、ローカル環境で Whisper を動かせるようにしました。
Whisper を動かせるようにするまで色々と作業が必要だったため、備忘録として作業内容を記録します。
環境
私のPC環境は次のとおりです。
- OS
- Windows 11 Pro 22H2
- Python
- 3.10.6
- グラフィックボード
- NVIDIA GeForce RTX 3060(メモリ12GB)
- NVIDIAドライバ
- バージョン535.50(執筆時点の最新版)
必要となるライブラリなど
Whisper の Github リポジトリの README.md では、「Whisper は Python 3.9.9 と PyTorch 1.10.1 を使ってトレーニングとテストをしているが、ソースコードは Python 3.8-3.11 と最近の PyTorch にも対応していると期待される」とあります。一方、PyTorch の最新版がサポートする Python のバージョンは 3.8-3.11 で、CUDA のバージョンは 11.7 か 11.8 です。
そのため、Python については元からインストールしている 3.10.6 を使い、PyTorch はバージョンが新しい方が使いまわしができるだろうと考えて最新版を使うことにしました。CUDA は参考にしたブログ記事では 11.7 を使っていましたので、それに倣うことにしました。
以上を踏まえてインストールしたライブラリは次のとおりです。
- Build Tools for Visual Studio2022
- CUDA Toolkit 11.7
- cuDNN (for CUDA 11.x)
- PyTorch (Stable (2.0.1))
それぞれのライブラリのインストール方法は次のとおりです。
Build Tools for Visual Studio2022のインストール
Microsoft の配布サイトからインストーラーをダウンロードして実行します。
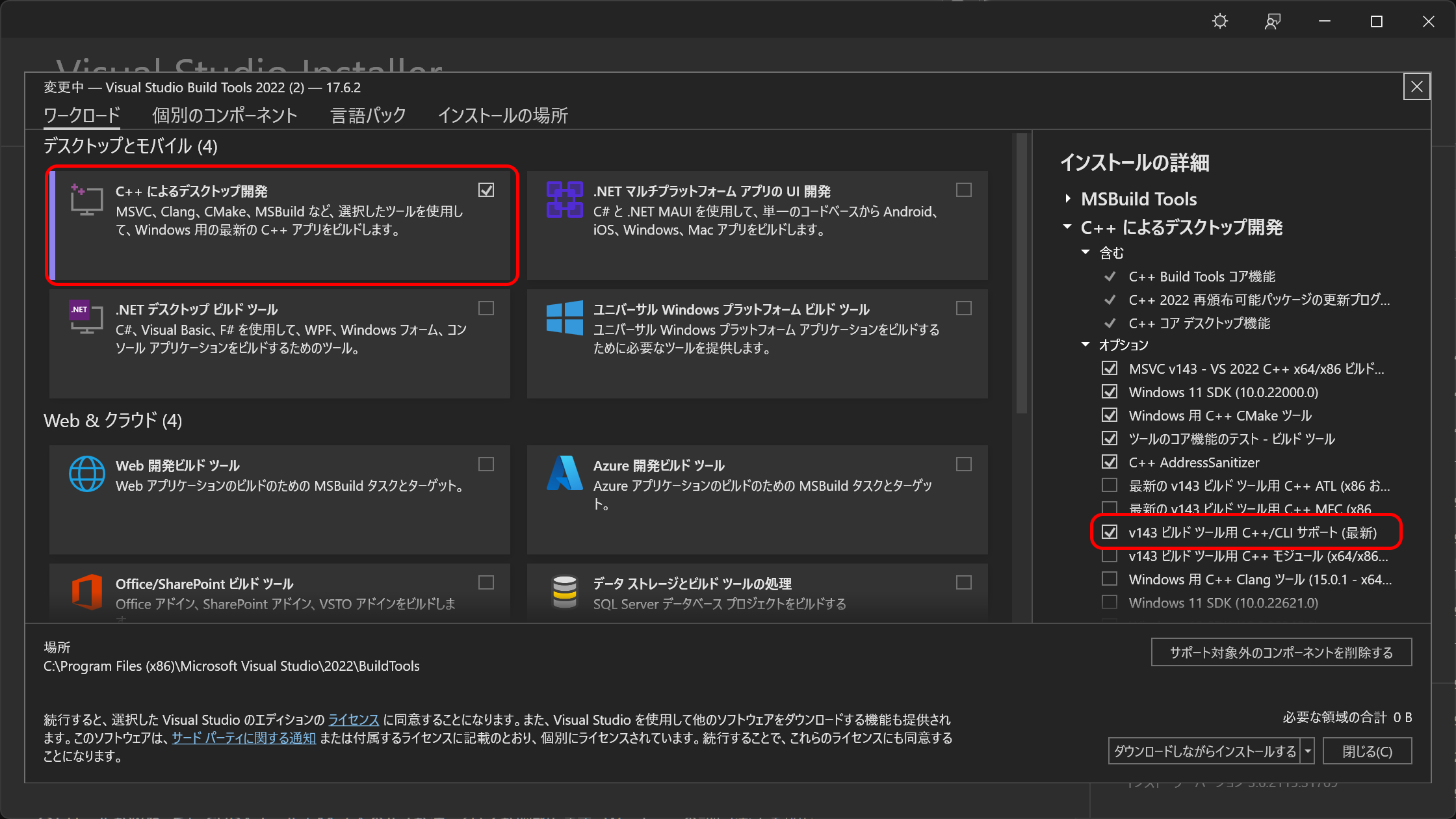
インストーラーを実行すると何をインストールするか聞かれますので、「C++によるデスクトップ開発」を選択し、右側に表示されるメニューから「v143ビルドツール用C++/CLIサポート(最新)」を選択してインストールします。私の環境では、最初のインストールは失敗に終わりましたが、インストール済みの古い C++ の再配布パッケージをアンインストールして再度インストールを実行したら無事にインストールできました。
CUDA Toolkit 11.7
NVIDIA の公式サイトからインストーラーをダウンロードして実行します。
実行するとインストールオプションで「高速(推奨)」と「カスタム(詳細)」を選択するよう求められます。
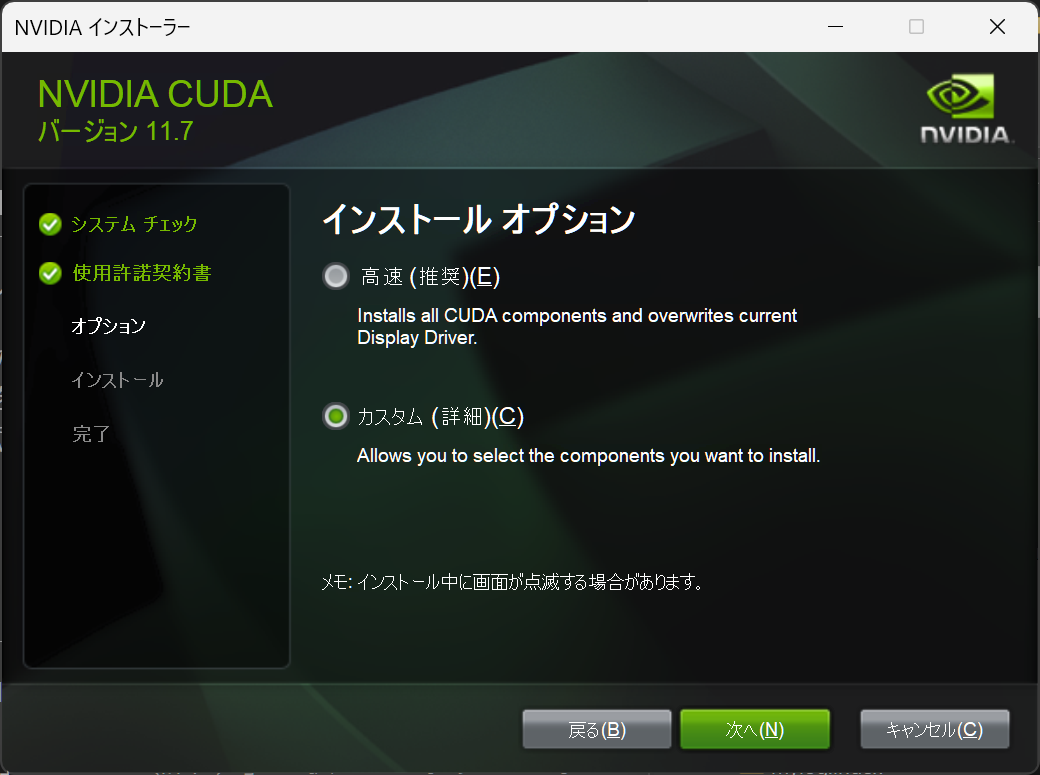
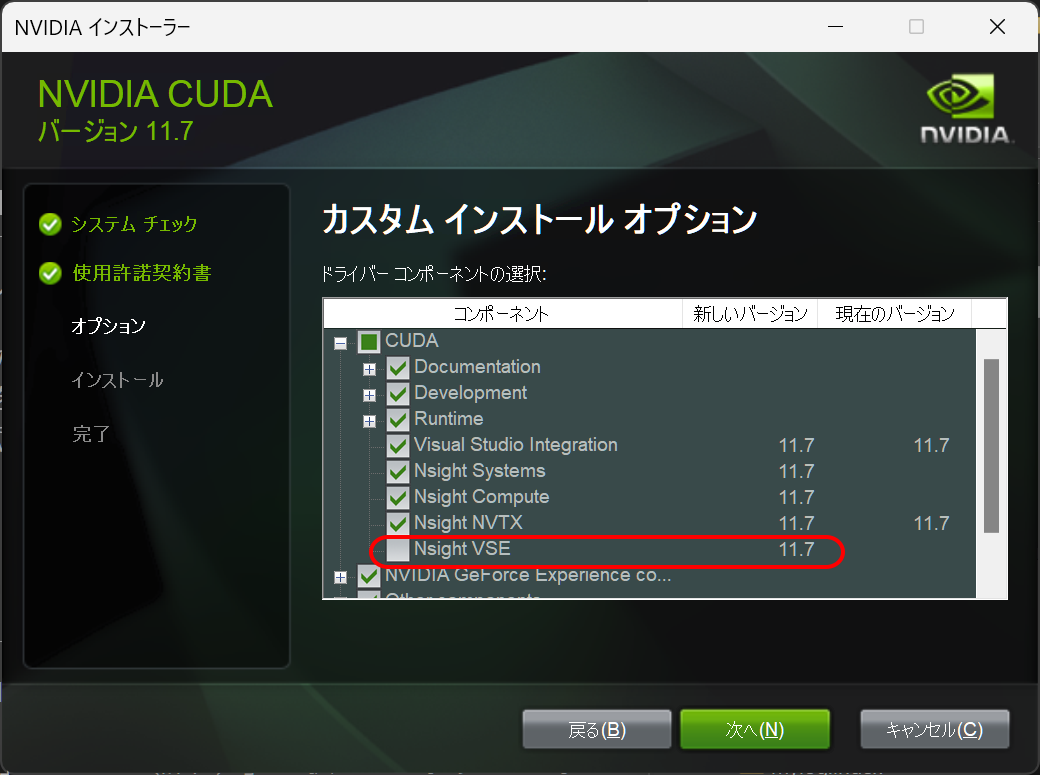
基本的には「高速(推奨)」を選べばよいと思うのですが、私の場合 nvidia nsight visual studio edition のインストールが失敗して全体のインストールも失敗しましたので、「カスタム(詳細)」を選択して nvidia nsight visual studio edition をインストール対象から除外してインストールしました。ちなみに、nvidia nsight visual studio edition は、Visual studio で GPU コンピューティングを開発する際にデバッグ等の機能を提供するツールのようです。
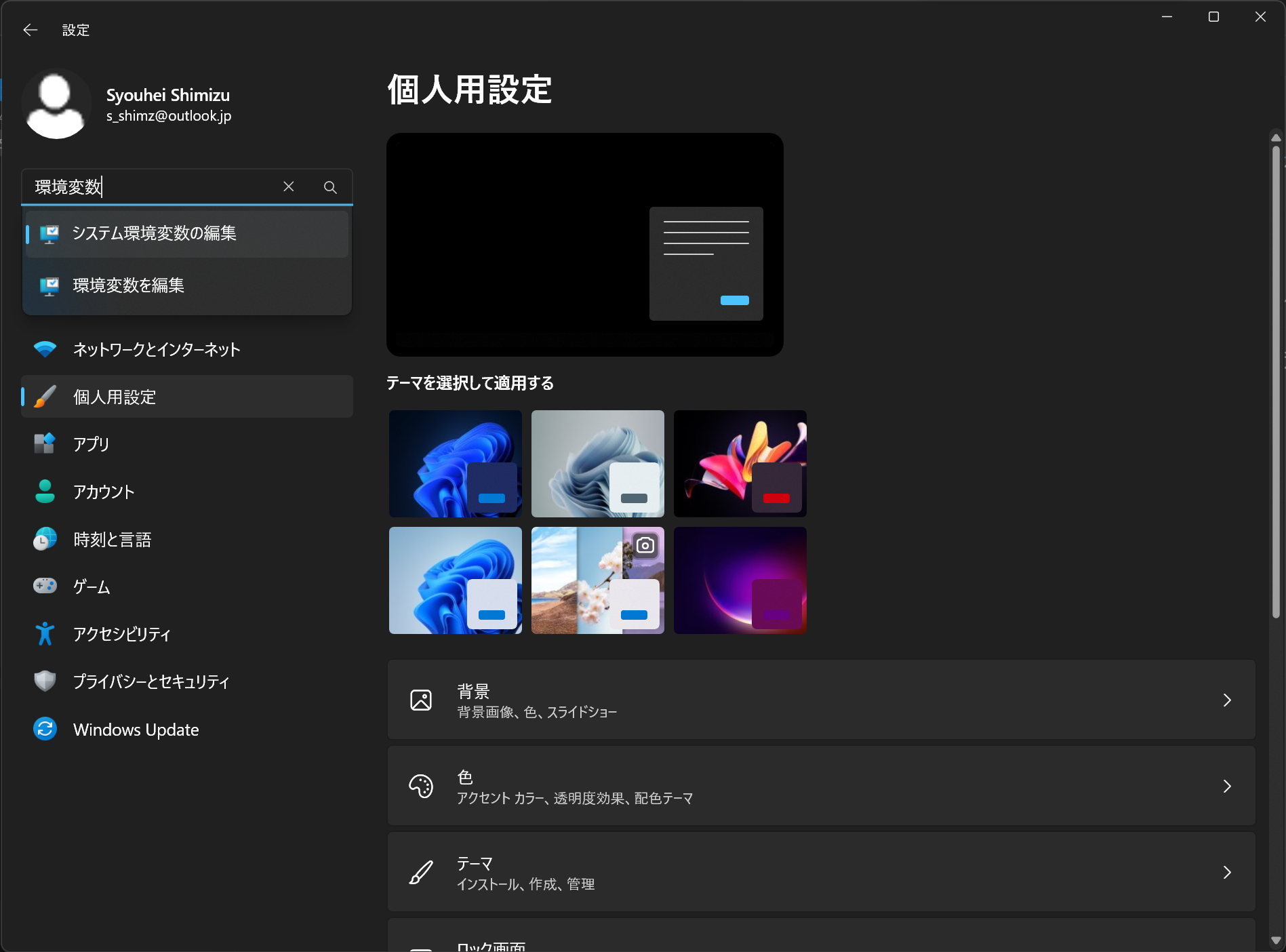
インストールが終わったら CUDA Toolkit 11.7 へのパスが通っているか確認します。Windows の設定画面を開いて左上の検索ボックスに「環境変数」と入力してから「システム環境変数」を選択し、出てきた画面の下側にある「環境変数」ボタンをクリックして設定画面を開きます。そして、システム環境変数の path に C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\bin と C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\libnvvp が設定されているか確認します。
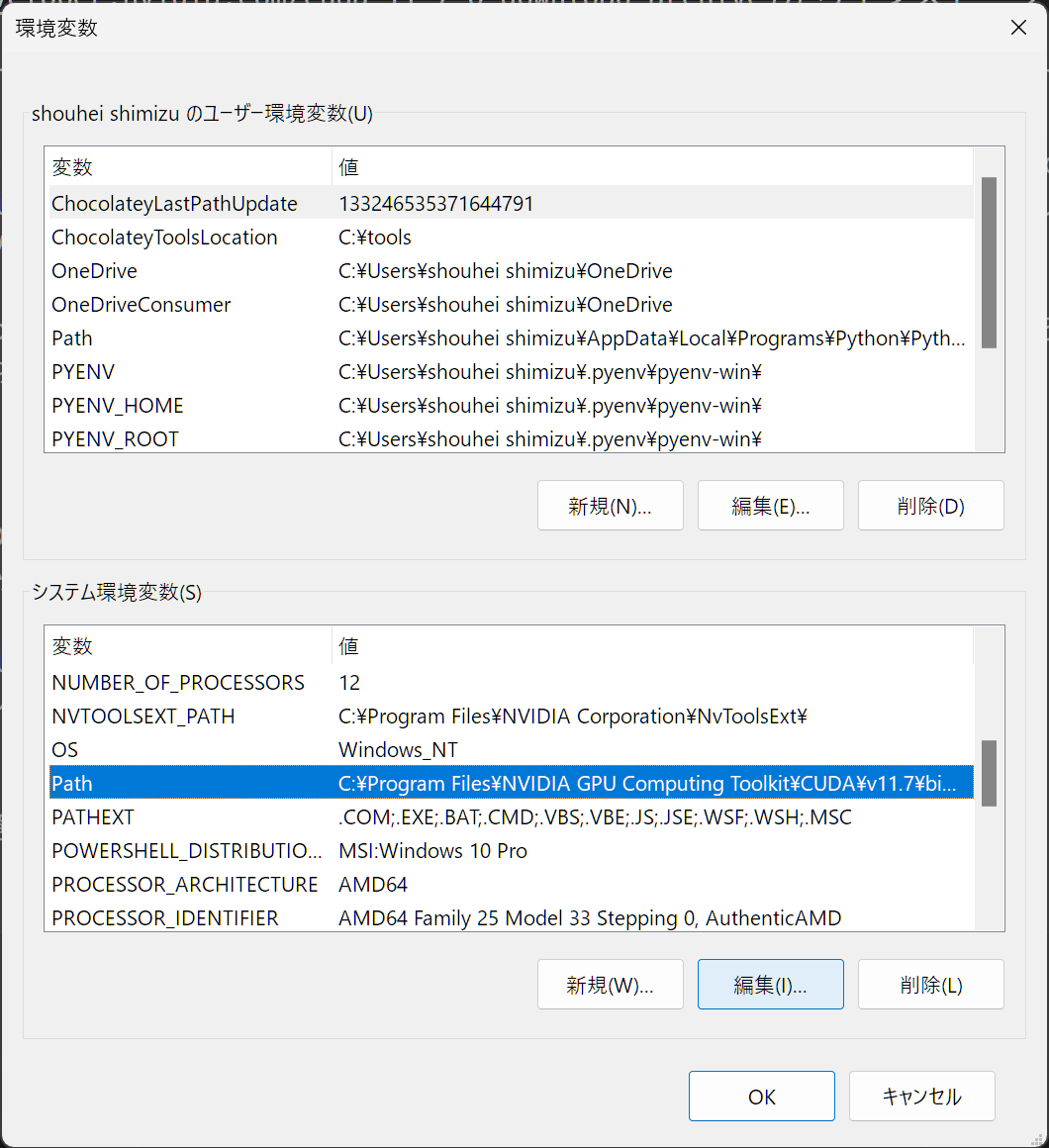
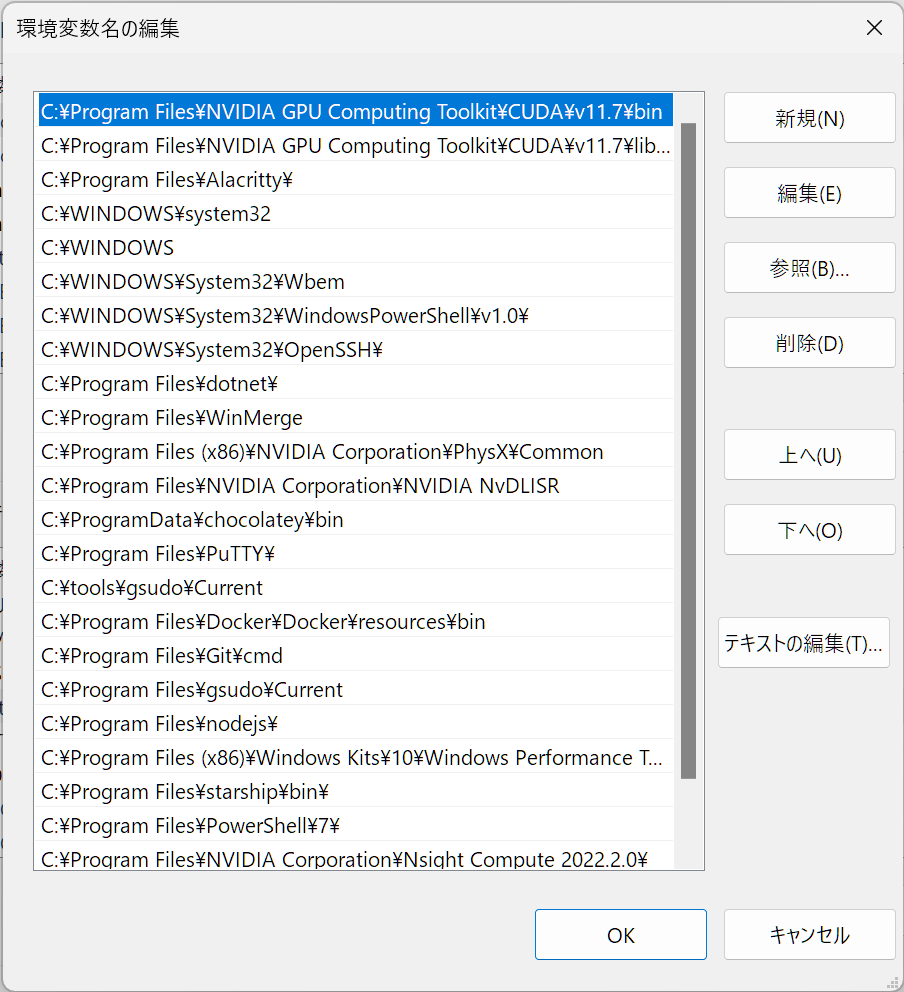
ここでパスが通っていることを確認したら、追加の確認として、コマンドプロンプトか PowerShell を開いて nvcc -V コマンドを実行します。インストールに成功してパスが通っていれば、次のような結果が表示されます。
1nvcc: NVIDIA (R) Cuda compiler driver
2Copyright (c) 2005-2022 NVIDIA Corporation
3Built on Tue_May__3_19:00:59_Pacific_Daylight_Time_2022
4Cuda compilation tools, release 11.7, V11.7.64
5Build cuda_11.7.r11.7/compiler.31294372_0
cuDNN
cuDNN は「The NVIDIA CUDA® Deep Neural Network library」の略で、GPU を使ったディープニューラルネットワークのためのライブラリです。公式サイトにアクセスしてインストーラーをダウンロードしますが、ダウンロードするには NVIDIA Developer に登録する必要があります。色々聞かれますので必須事項を1つ1つ答えて登録します。登録が完了したらインストーラーをダウンロードしますが、上記の作業で CUDA Toolkit 11.7をインストールしていますので、「CUDA 12.x」ではなく「CUDA 11.x」を選択します。
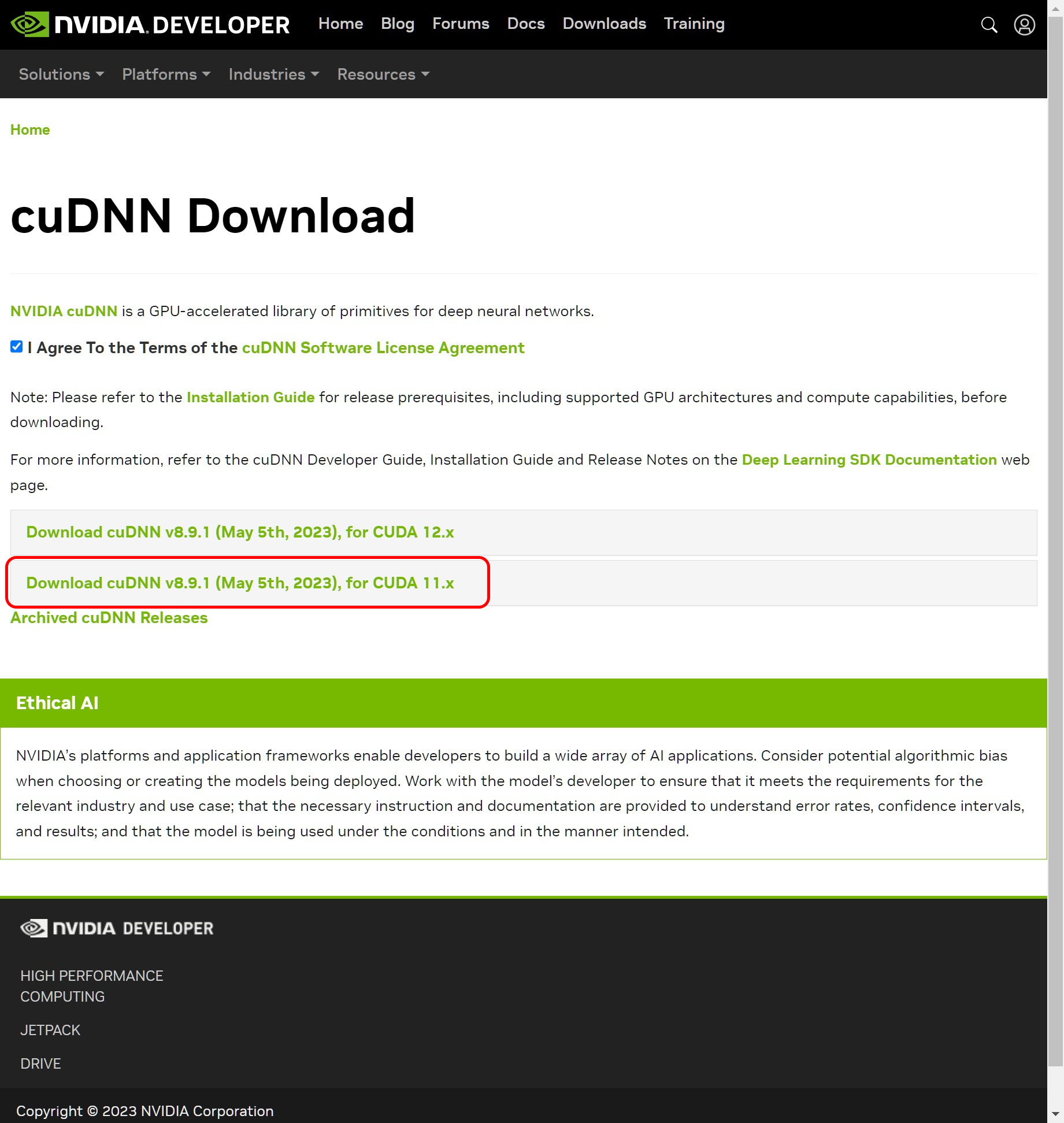
インストーラー(ZIPファイル)をダウンロードしたら、ダウンロードした ZIP ファイルを解凍するか Explorer で開きます。ZIPファイルには bin include lib フォルダが入っていますので、これらのフォルダを先程 CUDA をインストールしたフォルダ(例えば、C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\)の中にコピーします。
それから cuDNN へのパスを通します。こちらは CUDA Toolkit 11.7 とは違い自動的にパスが設定されませんので、先程と同様の手順でシステム環境変数の設定画面を開き、CUDA_PATH と同じ値を CUDNN_PATH として設定します。
Python の仮想環境を構築
やっと PyTorch をインストールしますが、システム全体にインストールすると今後思わぬところで依存関係のトラブルが起きそうな気がしましたので、Whisper 専用の仮想環境を用意してそこにインストールすることにしました。
仮想環境は venv を使って D:\voice2text_with_whisper_fp16 に用意することにしましたので、PowerShell を開いてこのディレクトリに移動した後 python -m venv .venv コマンドを実行して仮想環境を作成し、.venv\Scripts\activate.ps1 コマンドを実行して仮想環境に切り替えました。
PyTorch のインストール
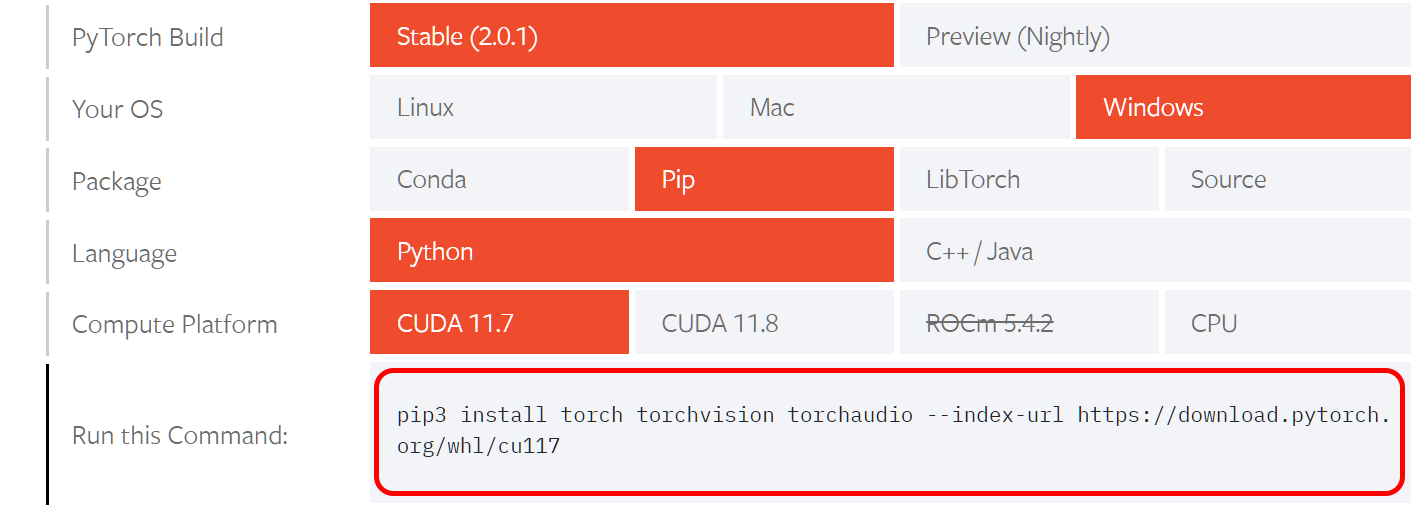
公式サイトで PyTorch のバージョンや OS の種類などを選択することで表示されるインストールコマンド (pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117) コマンドを実行して PyTorch をインストールします。
Whisper のインストール
ようやく下準備ができましたので、本命の Whisper をインストールします。公式リポジトリに掲載されている pip install git+https://github.com/openai/whisper.git コマンドを実行してインストールします。
音声ファイルの変換
これで必要な準備はできたはずですので、以下のコードを適当なファイル名 (voice2text.py) で保存してから、PowerShell を開いて python3 voice2text.py "音声ファイルへのパス" コマンドを実行して音声をテキストに変換します。
コードはWhisper + GPT-3 で会議音声からの議事録書き出し&サマリ自動生成をやってみる! - Qiitaを参考にしています。
1# 変換したテキストの保存場所とファイル名指定のためにインポート
2import datetime
3import os
4import sys
5sys.path.append(os.path.join(os.path.dirname(__file__), '.venv\lib\site-packages'))
6
7# 入力音声の変換に必要なライブラリのインポート
8import librosa
9import soundfile as sf
10import whisper
11
12# 下準備
13voiceFile = sys.argv[1]
14def generate_transcribe(file_path):
15 # Whisper高速化テクニック
16 # https://qiita.com/halhorn/items/d2672eee452ba5eb6241
17 model = whisper.load_model("large", device="cpu")
18 _ = model.half()
19 _ = model.cuda()
20
21 # exception without following code
22 # reason : model.py -> line 31 -> super().forward(x.float()).type(x.dtype)
23 for m in model.modules():
24 if isinstance(m, whisper.model.LayerNorm):
25 m.float()
26 result = model.transcribe(file_path)
27 return result
28
29# 音声ファイルのサンプリング
30y, sr = librosa.load(voiceFile)
31y_16k = librosa.resample(y, orig_sr=sr, target_sr=16000)
32n_samples = int(15 * 60 * 16000)
33
34# 音声ファイルを15分ごとに分割する
35segments = [y_16k[i:i+n_samples] for i in range(0, len(y_16k), n_samples)]
36
37# 分割した音声ファイルを保存する
38for i, segment in enumerate(segments):
39 sf.write(f"./splited_voice_file_{i}.wav", segment, 16000, format="WAV")
40
41# 分割した音声ファイルを順番にテキストに変換
42transcript = ""
43for i in range(len(segments)):
44 # print(fc.selected_path)
45 file_path = f"./splited_voice_file_{i}.wav"
46 transcribe = generate_transcribe(file_path)
47 for seg in transcribe['segments']:
48 transcript += seg['text'] + "\n"
49
50# 変換したテキストをこのスクリプトと同じディレクトリに保存。
51# ファイル名は日付 + 時間
52now = datetime.datetime.now()
53filename = now.strftime('%Y%m%d_%H%M')
54f = open(filename + '.txt', 'w')
55f.write(transcript)
56f.close()
ちなみに、音声は Microsoft Store からインストールした Windows ボイスレコーダーで録音しています。